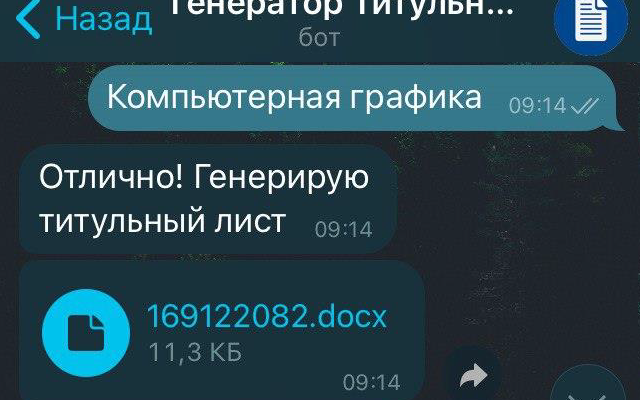
Бот-генератор титульных листов
Вам лень делать очередную работу, но нужно хотя бы с чего нибудь начать? Мы сделали для Вас бота, который решит эту задачу, сгенерировав титульный лист!
История проекта
В нашем университете, как известно, много институтов, на каждом институте много кафедр, а на каждой кафедре работает много преподавателей. Почти у каждого преподавателя есть свои требования к титульному листу (например, предоставление с подписью, без неё, в .docx, .pdf). Соответственно, под эти требования пишется не одна сотня различных титульных листов ежемесячно. Это отнимает некоторое количество времени: там вставить фамилию, тут имя, а здесь все съехало, и так далее. Более того, титульные листы на сайте ГУАП расположены довольно глубоко и их довольно трудно найти.
Собравшись командой, мы поняли, что будет довольно здравым решением автоматизировать этот процесс, чтобы впредь на это не тратить столько времени, сколько сейчас.
На проект у нас было отведено чуть меньше месяца. За это время нам нужно было: понять, в каком виде мы будем реализовывать генератор, какими инструментами мы будем пользоваться, и что мы вообще сами от себя хотим, и реализовать его.
Почти сразу же мы решили писать бота в Telegram. Это – один из самых лучших вариантов, потому что сегодня этот мессенджер зачастую открыт на компьютерах потенциальных пользователей: кто то листает каналы, кто то сидит в чатах, у кого то просто на фоне открыт.
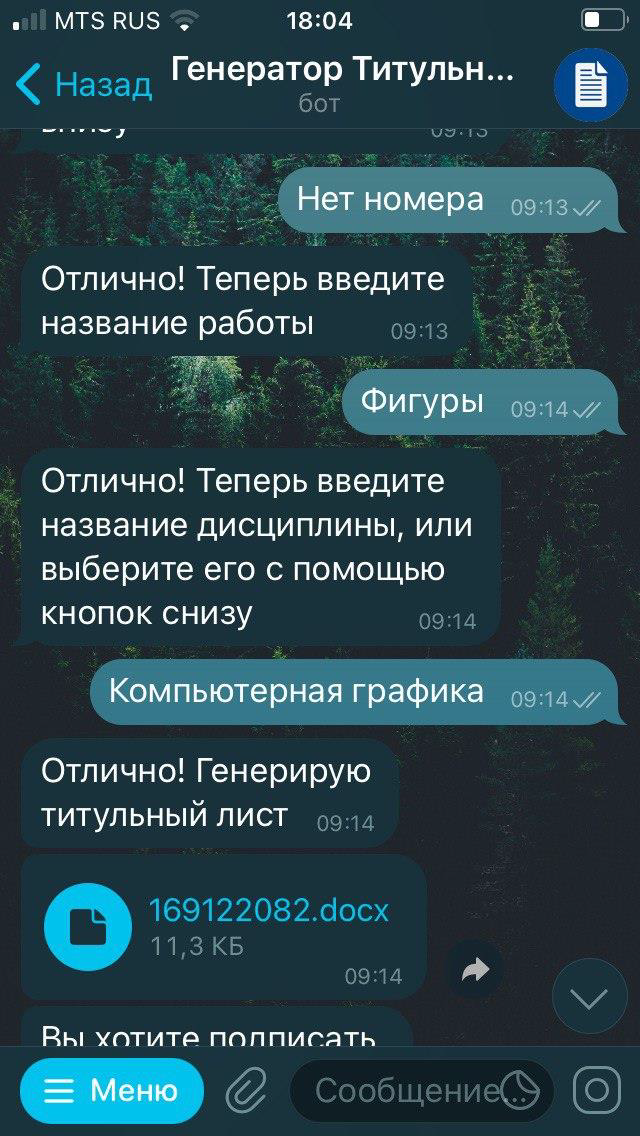
Мы выделили несколько модулей: скачивания, парсинга, обработки, подписи, конвертации (подробнее ниже), сам бот – это для того, чтобы каждый мог внести свой вклад в развитие проекта.
Затем мы набросали структурную схему нашего проекта. В ней мы отразили все взаимосвязи между модулями, то есть какие данные к какому модулю идут, и какие данные возвращаются в ответ.
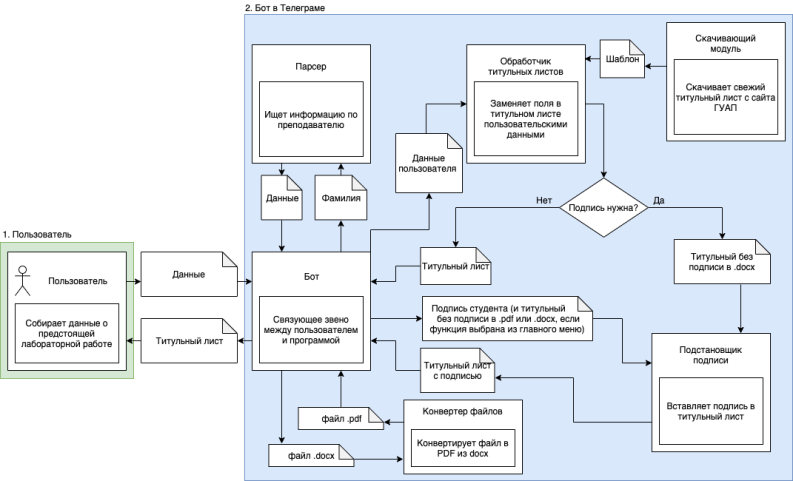
После этого мы начали писать сами модули (практически все одновременно, потому что количество людей в команде позволяло), попутно изучая документацию тех или иных библиотек или API. После написания каждого модуля, те тестировались, а затем подключались к боту, заменяя соответствующие «заглушки» своим функционалом. Естественно, в ходе тестирования возникали те или иные проблемы, которые решались либо переписыванием кода, либо изменением архитектуры модуля и/или проекта.
Мы успели сделать все, что запланировали, но времени на программу «максимум» (генерацию подписей по ФИО) уже не хватило.
Описание проекта
Расскажем подробнее о самих модулях.
Модуль-парсер
Задачей этого модуля является парсинг одного из сайтов ГУАП с целью поиска информации о преподавателе по его фамилии.
Сначала мы использовали связку библиотек requests и BeautifulSoup4 для Python, которые работали на сайте rasp.guap.ru. У этого метода несколько плюсов: высокая скорость работы за счет маленького объёма сайта, нет необходимости ставить сторонние программы. Однако минусом, и довольно серьезным, является невозможность получить номер кафедры, на которой работает искомый преподаватель, а также вытащить полные данные о его ученой степени, звании, должности на кафедре.
Такой подход мы довольно быстро отбросили и переписали парсинг на библиотеку Selenium. Благодаря ей мы смогли парсить динамические сайты и переехать на pro.guap.ru, в котором содержатся все необходимые данные. Парсинг выглядит теперь так: модуль открывает браузер на странице, ждет появления строки поиска, вводит туда фамилию преподавателя, ждет конца загрузки, получает ID преподавателей, которые спрятаны в ФИО преподавателя в соответствующих тегах <a>, вызывает метод API ЛК ГУАП, который возвращает все данные по пользовательскому ID, собирает массив таких ответов и отправляет боту.
Конечно, такой метод куда более медленный и требует дополнительных ресурсов на открытие браузера, а также сбор ответов на запрос, однако дает в результате больше данных.
Скачивающий модуль
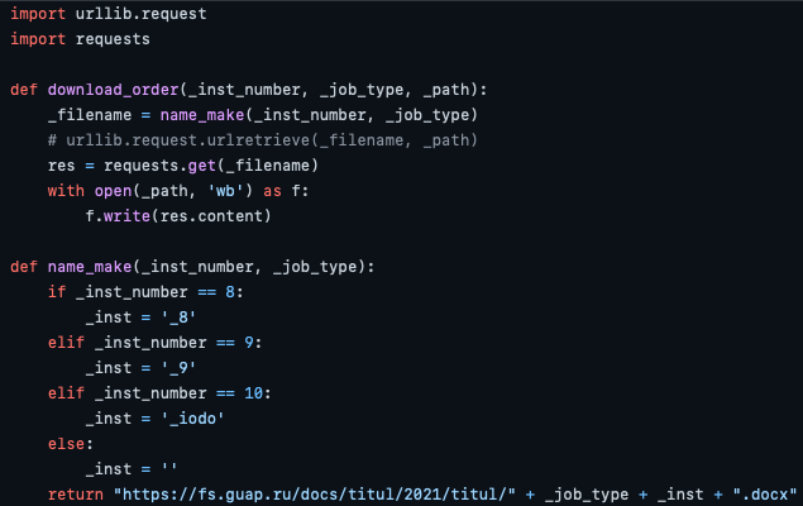
Задача этого модуля — скачивать свежий титульный лист с файлового сервера ГУАП для нужной работы.
На вход ему подается номер института студента, тип работы, а также путь, по которому нужно сохранить полученный файл. В процессе разработки мы поняли, что три варианта титульных листов, которые там находятся, отличаются друг от друга лишь названиями кафедр, которые там вставлены, поэтому номер института является ненужным параметром, но убрать его мы не успели, потому что все время откладывали, так что извне номер института ставится равным 1.
Тут сперва использовалась библиотека urllib, однако при дальнейшем тестировании вскрылась ошибка проверки сертификата сайта, из-за которой подключение к fs.guap.ru срывалось. Так что мы переехали на библиотеку requests, что оказалось даже более читаемо.
Обработчик титульных листов
Задача этого модуля — создавать нужный титульный лист из шаблонного.
На вход ему подается массив данных, формируемый на стороне бота, а также путь, по которому находится уже скачанный титульный лист.
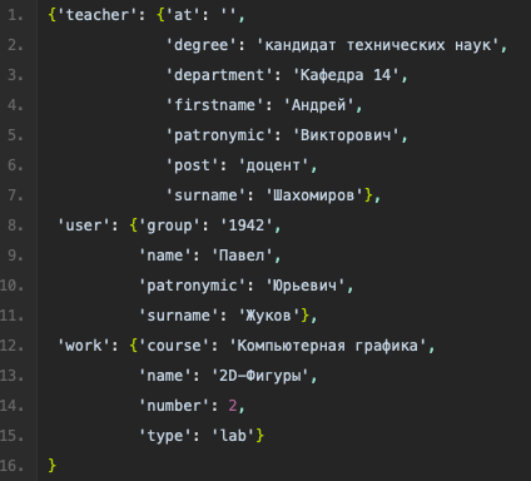
Дальше происходит довольно простая операция подстановки текста в нужные ячейки, а также замена текста, например, номера кафедры.
Тут возникли две проблемы: при смене текста оформление этого текста сбивается напрочь, выставляется стандартное для данного документа, а также появилась необходимость создавать сокращения для названия должности, ученой степени, и так далее. Первую проблему мы решили ручной установкой стилей в каждой замененной ячейке или строке, а вторую — с помощью создания словаря сокращений.

После работы модуля готовый титульный лист сохраняется по переданному в начале пути.
Здесь мы выбрали библиотеку python-docx, и её не меняли.
Постановщик подписи
Задача этого модуля — вставить подпись в титульном листе на соответствующее место.
В этом модуле предусмотрены две функции: для подписания docx и pdf файлов. Обе они принимают путь к файлу и путь к подписи студента. Для docx все довольно просто — вставить картинку в нужную ячейку таблицы, что мы и делаем. Тут возникает проблема, которую мы до сих пор не можем решить — изображение растягивается на всю ячейку, не остается места под дату. Для работы с docx использовалась библиотека python-docx.
В PDF мы получаем первую страницу документа, ищем там второе вхождение слов «подпись, дата» (первое — для преподавателя), смещаем полученный прямоугольник несколько наверх, чтобы подпись находилась в нужном поле, и вставляем картинку подписи. Тут все работает очень даже хорошо, единственная проблема — выбор библиотеки. Сперва мы пробовали библиотеку PyMuPDF вместе с PText, однако последняя странно определяла границы текста, так что мы отбросили её, оставшись только на PyMuPDF.
Конвертер файлов
Изначальная задача — конвертировать титульные листы из docx в PDF.
Модуль принимает путь к файлу, по ко второму находится исходник.
Тут была одна серьёзная проблема — сперва использовалась библиотека docx2pdf, а она требует установки Microsoft Office Word, что неприменимо в случае выгрузки бота на сервер. Поэтому мы нашли сервис по конвертации PDF, который предоставляет удобное API, и подключили его к нашему модулю. Единственный минус у такого метода — по бесплатному тарифу можно конвертировать всего лишь 250 файлов, чего, естественно, недостаточно для нормальной коммерческой работы.
Бот
Бот отвечает за коммуникацию с пользователем и сбор данных от него. Он работает библиотеке aiogram и представляет, по сути, набор функций, обернутых в различные обработчики событий.
Логика бота отражена в схеме ниже.
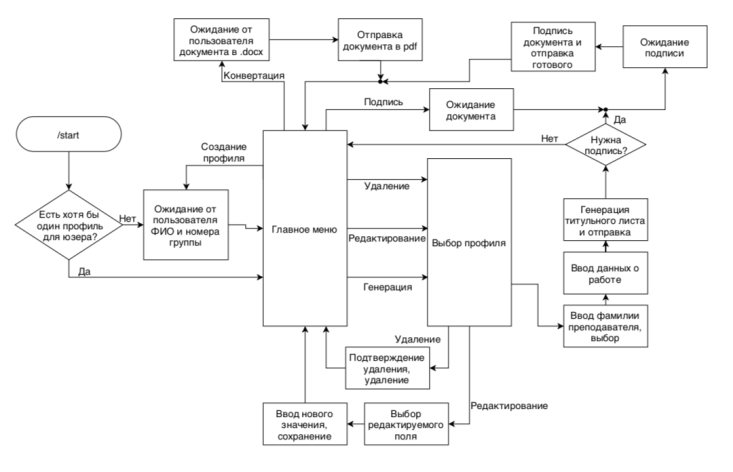
При разработке бота возникло несколько сложностей: изначально была выбрана неверная машина состояний, из-за чего был потенциально очень медленный алгоритм установки состояний, а также отсутствовала возможность сохранения данных в этой машине. Решением данной проблемы стал переезд на другую организацию машины состояний.
Вторая проблема — организация базы данных для хранения профилей пользователей, чтобы не вводить по много раз одно и то же. Мы выбрали хранить данные в стопке JSON файлов, по одному на пользователя. Такой подход, конечно, довольно хорош, но при выгрузке бота на Heroku обнаружилось, что по завершении бота все созданные им файлы удаляются, то есть каждый раз происходит, по сути, drop database. Эту проблему мы так и не решили, но планируем решить путем переезда на нормальную базу данных, например PostgreSQL.
Заключение
В результате плодотворной работы нашей команде удалось в сжатые сроки сделать проект, который на 95% удовлетворяет тем задачам, что мы ставили перед собой. Осталось только подправить некоторые проблемы, а также добавить несколько функций, и проект будет полностью готов.
Ссылки
- Работа бота за 30 секунд – https://youtu.be/fqolAE3dSuE
- Репозиторий с исходным кодом – https://github.com/Dimitryliss1/TitulGen
- Про машину состояний и учебник по aiogram
- Документации библиотек
- https://pymupdf.readthedocs.io/en/latest/tutorial.html — PyMuPDF
- https://docs.aiogram.dev/en/latest/ — aiogram
- https://python-docx.readthedocs.io/en/latest/index.html — python-docx
- https://github.com/AndyCyberSec/pylovepdf — pylovepdf
- https://docs.python-requests.org/en/master/user/quickstart/ — requests
- https://beautiful-soup-4.readthedocs.io/en/latest/ — Beautiful Soup 4
Команда
Данный проект делали шесть студентов-второкурсников кафедры аэрокосмических приборов и систем:
- Жуков Павел, группа 1942 (Telegram) — разработка бота, а также багфикс модулей
- Марков Константин, группа 1942 (Telegram) — разработка модулязагрузчика титульных листов
- Шевнин Лев, группа 1942 (Telegram) — разработка модуля-парсера
- Иванов Никита, группа 1941 (Telegram) — разработка модуля-конвертера
- Калинин Артём, группа 1941 (Telegram) — разработка модуля-постановщика подписи
- Янин Сергей, группа 1941 (Telegram) — разработка модуля-обработчика титульных листов